Selenium 入门(基于 Python)

Selenium 入门(基于 Python)
丁俊尧自从转岗以来,我充分接触 Selenium 已经有一年了。在此期间,主管一直想让我出一些关于自动化测试的教育训练,但是由于工作太忙,加上一开始是要从 Python 开始做的,所以我找资料找了很久,都没有什么头绪。
最近,主管又催我做一套自动化测试的 PPT,于是我花了两天的时间,把 Selenium 最基础的东西做成了 PPT。但是主管和其他同事看了一下,觉得 PPT 介绍得太详细,已经不需要我去讲了,所以最后也没有让我讲它(后来还是讲了)。
总之,我现在把它放出来,加上我的讲稿(虽然是我后来写的)。之后的内容在做了,不过也不知道什么时候做好——也许永远也做不好,也许明天就能做好。
在开始之前,我假定你们了解 Python 和 HTML、CSS、JS 的基础知识。
介绍
Selenium 是一款 Web 自动化框架,它适用于多种语言,包括 Python。
它并非直接控制浏览器,而是通过操作浏览器驱动(由浏览器厂家提供),实现对浏览器的操作。
除了 Web 自动化测试之外,它也可用于自动化和爬虫——我大三的时候爬 QQ 空间的数据,模拟登录就用了 Selenium。
Selenium 的替代产品也有一些,最近比较有名的是微软出品的 Playwright,也支持 Python 在内的很多语言。我研究过这个工具,虽然它对元素的自动等待比较好,不过它在处理提示框上面不尽人意,而且它也不支持元素的嵌套。对于 Playwright,中文的资料不多,我可能会在以后出一期关于它的介绍。总之,这次还是讲 Selenium 的。
安装
Python 中,Selenium 的安装方式和其他模块一样,用 pip 安装:
1 | pip install selenium |
然后,根据自己使用的浏览器和版本下载浏览器驱动。
- Chrome:chromedriver(http://chromedriver.storage.googleapis.com/index.html)
- Firefox:geckodriver(https://github.com/mozilla/geckodriver/releases/)
- Edge:Microsoft Edge Driver(https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/)
- IE:The Internet Explorer Driver Server(https://www.selenium.dev/downloads/)
将下载的浏览器驱动的可执行文件放到 Path 下。注意,不要放在网络文件夹下,一些驱动无法在网络文件夹下使用。如果你不知道什么是 Path,看一下下面的介绍。
关于 Path
简单来说,在终端执行命令时,如果不指定路径,系统会在系统环境变量中的 Path 里面的路径中找命令所属的可执行文件。
在 Windows 中,可以在“设置 - 系统 - 关于 - 高级系统设置 - 环境变量”中更改环境变量。
如果因为管理员权限,无法通过上述方式更改环境变量,可在 PowerShell 中执行下面的命令:
$env:Path返回目前的环境变量,复制下来;- 在复制的环境变量中(一般为末尾)添加新的路径,参照已有环境变量写,末尾有英文分号;
- 重新写入环境变量:
[environment]::SetEnvironmentvariable("Path", "新的环境变量字符串", "User")
讲解
接下来我们用一个示例来学习 Selenium 的基础知识。虽然很简单,但也覆盖了绝大部分内容。
示例
1 | import time |
以下是该代码的执行效果:
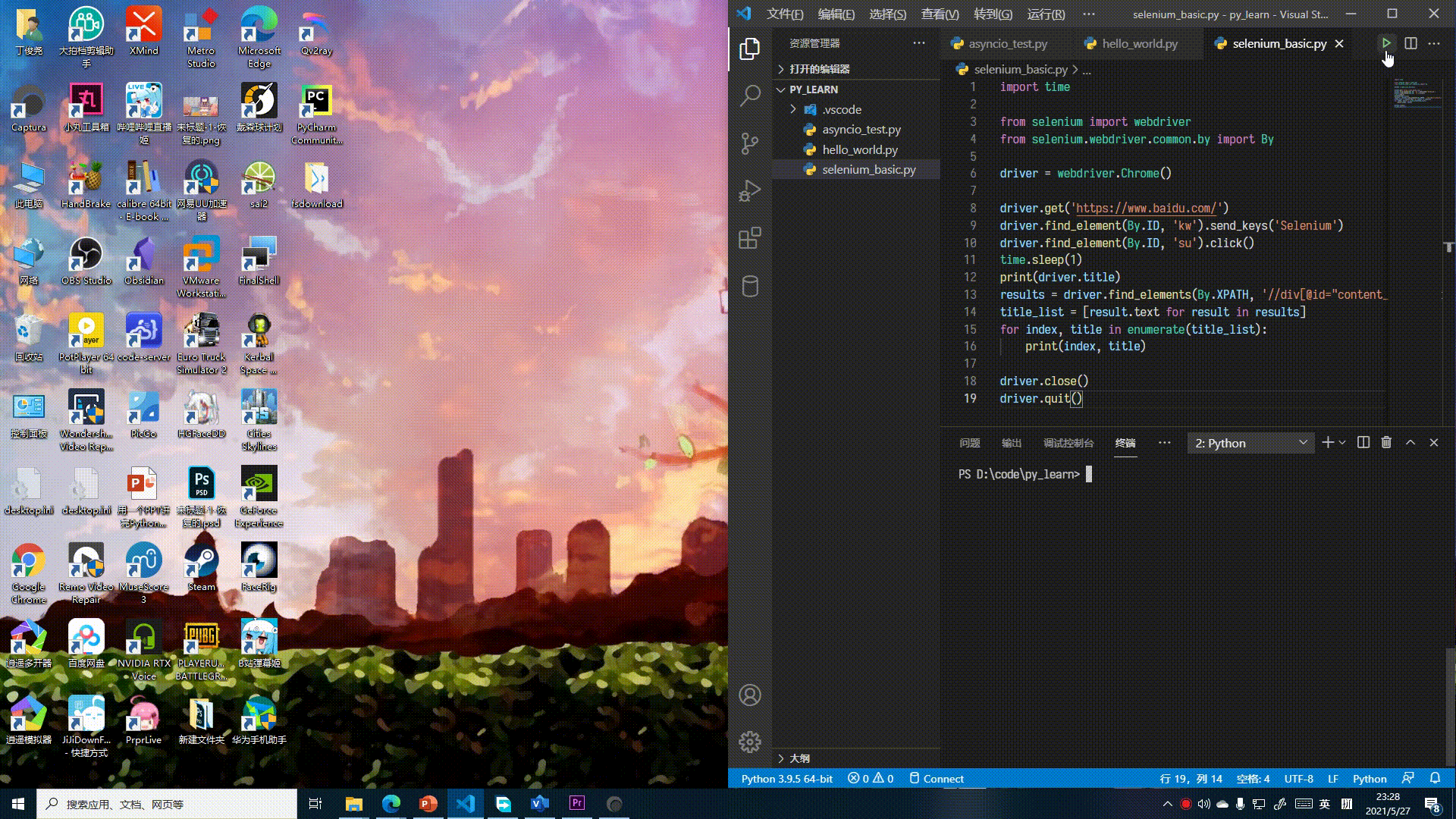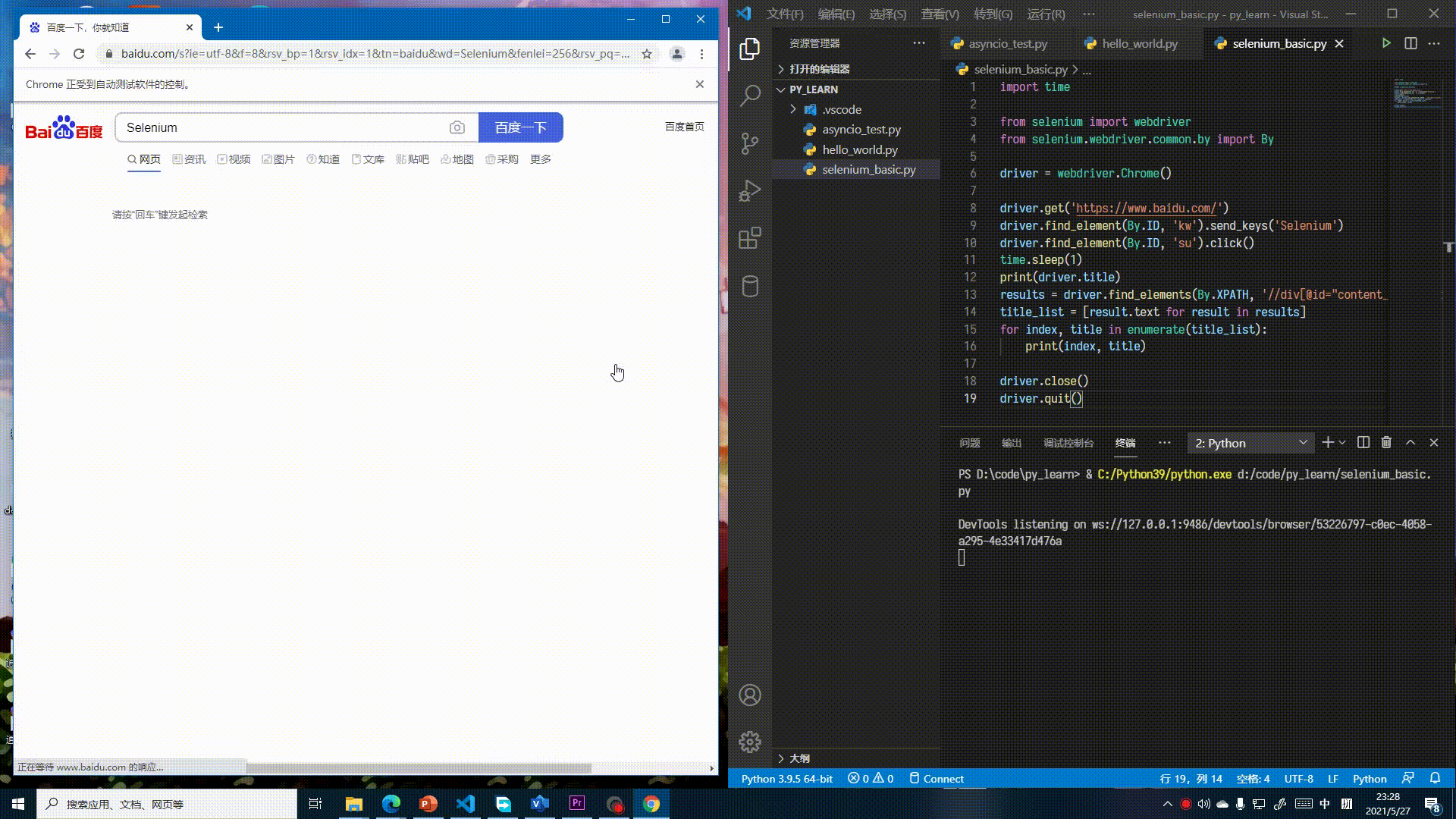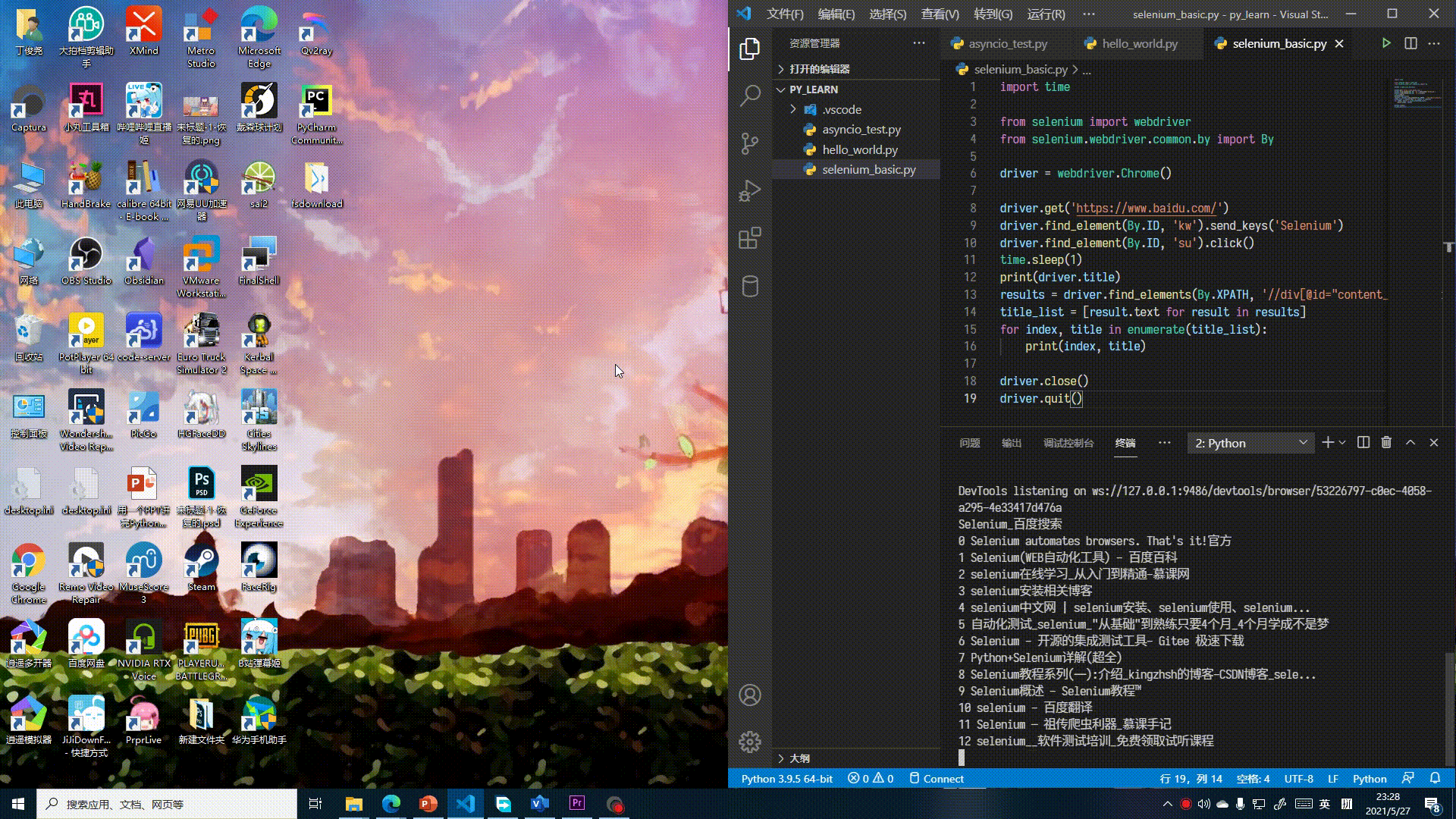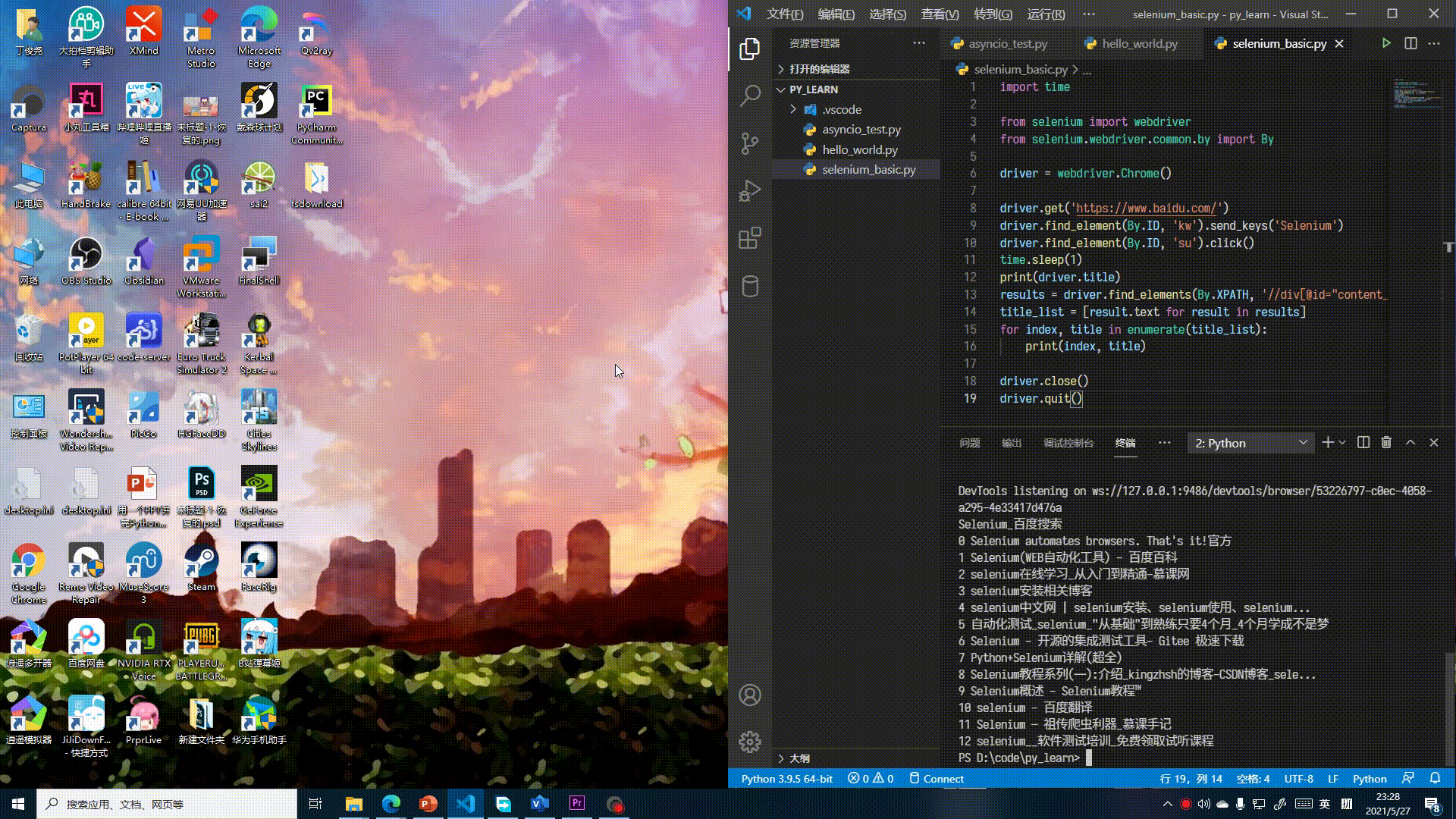
实际上就是在百度中搜索“Selenium”,再打印出第一页的标题和搜索结果标题。
接下来,我们看一下它是怎么运行的吧。
创建 WebDriver 实例
代码的第 3 行和第 6 行:
1 | from selenium import webdriver |
第 6 行创建了一个基于 Chrome 的 WebDriver 实例。接下来的所有操作在该实例上进行。
如果要用其他的浏览器,把 Chrome 换成别的浏览器名称,如 Firefox。具体的可以看源码。
访问网页
代码第 8 行:
1 | driver.get('https://www.baidu.com/') |
访问给定的网页。给定的 URL 需要写明协议(就是上例中的 https://),否则会报错。
寻找单个元素
代码第 4 行和第 9 行:
1 | from selenium.webdriver.common.by import By |
要想对网页上的元素进行操作,首先要寻找网页中的元素。Selenium 中寻找元素的最基础的方法,是对 WebDriver 实例调用 find_element() 方法。
该方法需要两个参数:
- 定位方式
- 查找文本
如果查询到元素,会返回一个 WebElement 实例,表示符合查询条件的第一个元素。如果查不到,会抛出 NoSuchElementException 异常。
对于 WebElement 实例,我们可以继续调用该方法,以查找隶属于该元素的元素。
定位方式
Selenium 提供 8 种定位方式:
- 使用元素 ID 定位
- 使用 XPath 定位
- 使用链接文本定位
- 使用链接文本的一部分定位
- 使用元素的
name属性定位 - 使用元素的标签名定位
- 使用元素
class定位 - 使用 CSS 选择器定位
传入 find_element() 方法的第一个参数决定定位方式,为字符串。不过通常情况下,我们会导入 Selenium 提供的定位方式包(见代码第 4 行),从中调用值。
每一个定位方式都有对应的别名方法,也就是定义了名称不同的方法,实质仍然是调用之前提到的的方法。这些别名方法的名称其实就是在原方法的名称后面加上 _by_...,调用它们只需要传入查找文本就行了。比如:
1 | driver.find_element(By.ID, 'kw') |
上面两行代码等价。
所有定位方式的值和别名方法见下表:
| 定位方式 | 字面量 | 含义 | 对应别名方法 |
|---|---|---|---|
By.ID |
'id' |
使用元素 ID 定位,默认值 | find_element_by_id() |
By.XPATH |
'xpath' |
使用 XPath 定位 | find_element_by_xpath() |
By.LINK_TEXT |
'link text' |
使用链接文本定位 | find_element_by_link_text() |
By.PARTIAL_LINK_TEXT |
'partial link text' |
使用链接文本的一部分定位 | find_element_by_partial_link_text() |
By.NAME |
'name' |
使用元素的 name 属性定位 |
find_element_by_name() |
By.TAG_NAME |
'tag name' |
使用元素的标签名定位 | find_element_by_tag_name() |
By.CLASS_NAME |
'class name' |
使用元素 class 定位 |
find_element_by_class() |
By.CSS_SELECTOR |
css selector |
使用 CSS 选择器定位 | find_element_by_css_selector |
上述定位方式中,我们要重点关注 XPath 和 CSS 选择器定位,这两种定位方式能够实现的功能非常强大,而且很常用。关于这两个选择器,我之后应该会出一期专门讲。
查看页面元素定位
通过浏览器的开发人员工具,能够方便地查看页面上的元素定位。
调用开发人员工具,一般按 F12 即可。
我们以 Chrome 的开发人员工具为例:
按工具窗口左上角的按钮(或按 Ctrl + Shift + C),在页面上选取元素,能够查看元素在源代码中的位置,以及元素的参数等信息,方便定位。
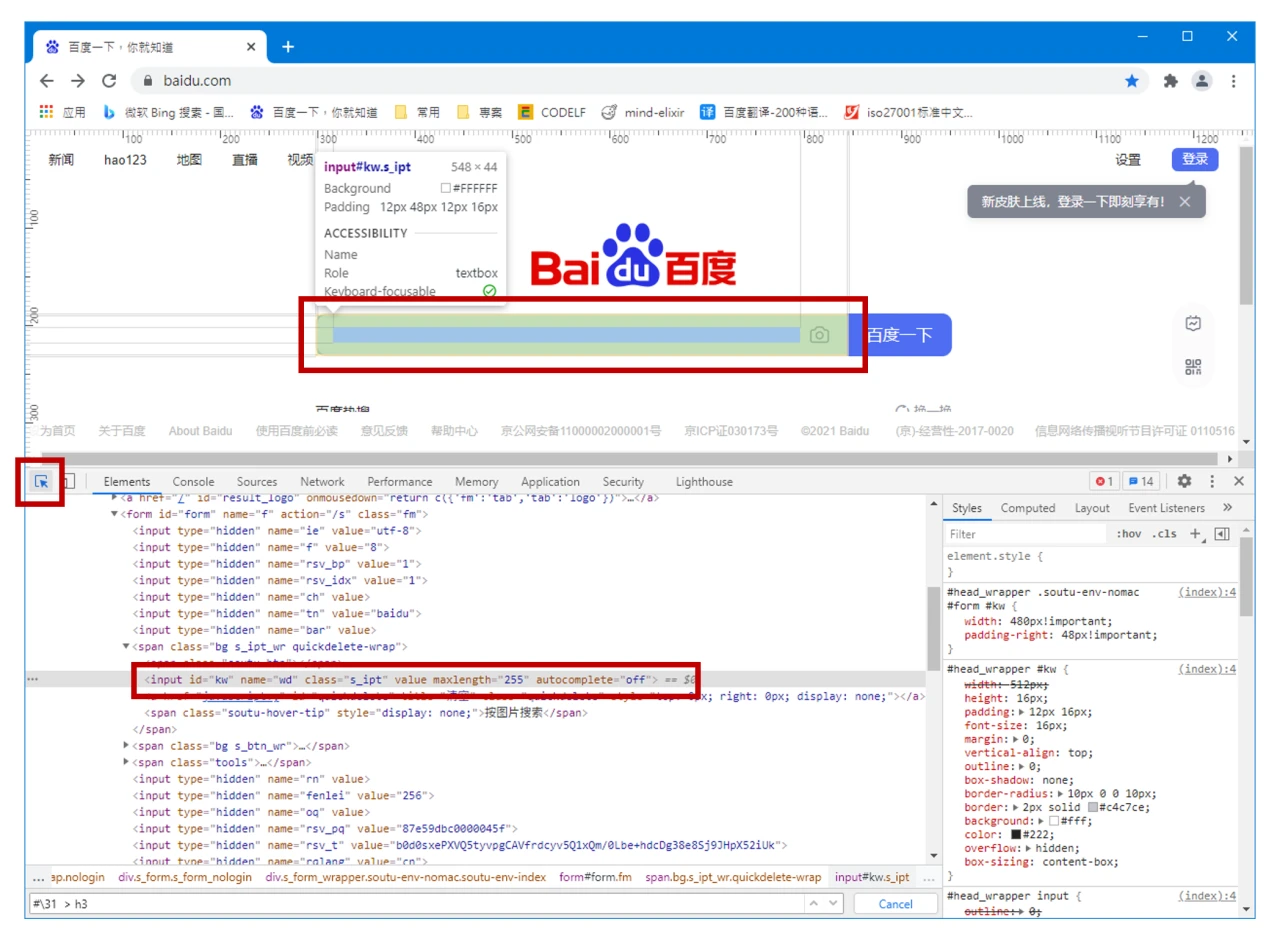
在 Elements(元素)选项卡中,按 Ctrl + F 调出查询栏,输入文本、XPath、CSS 选择器文本,可以查询对应的元素。
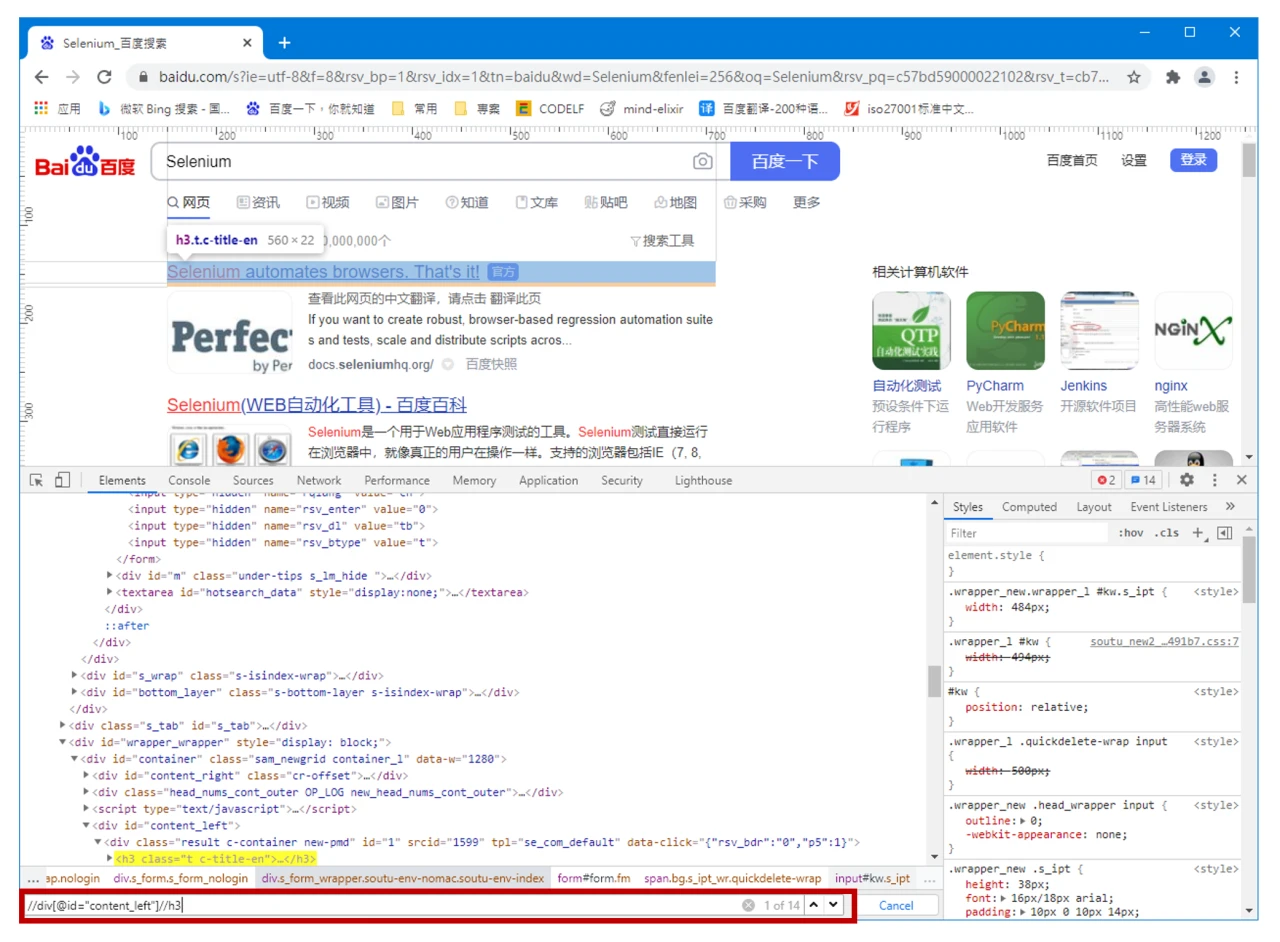
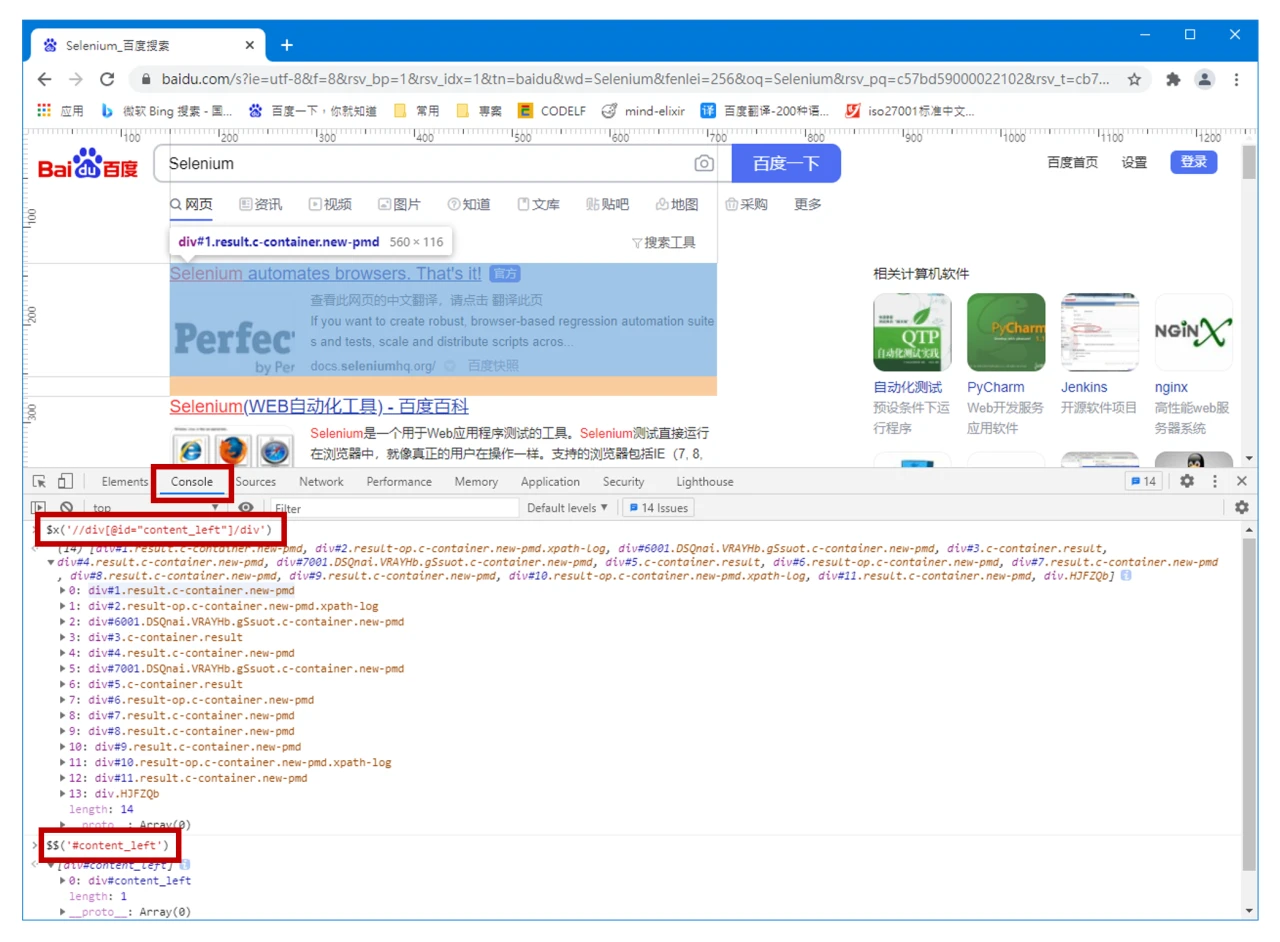
切换到 Console(控制台),输入 $x('XPath 文本') 或 $$('CSS 选择器文本'),回车,可以返回对应的元素。有时候,输入完毕,也可以先不用回车,根据是否能看到结果来初步判断文本是否正确。
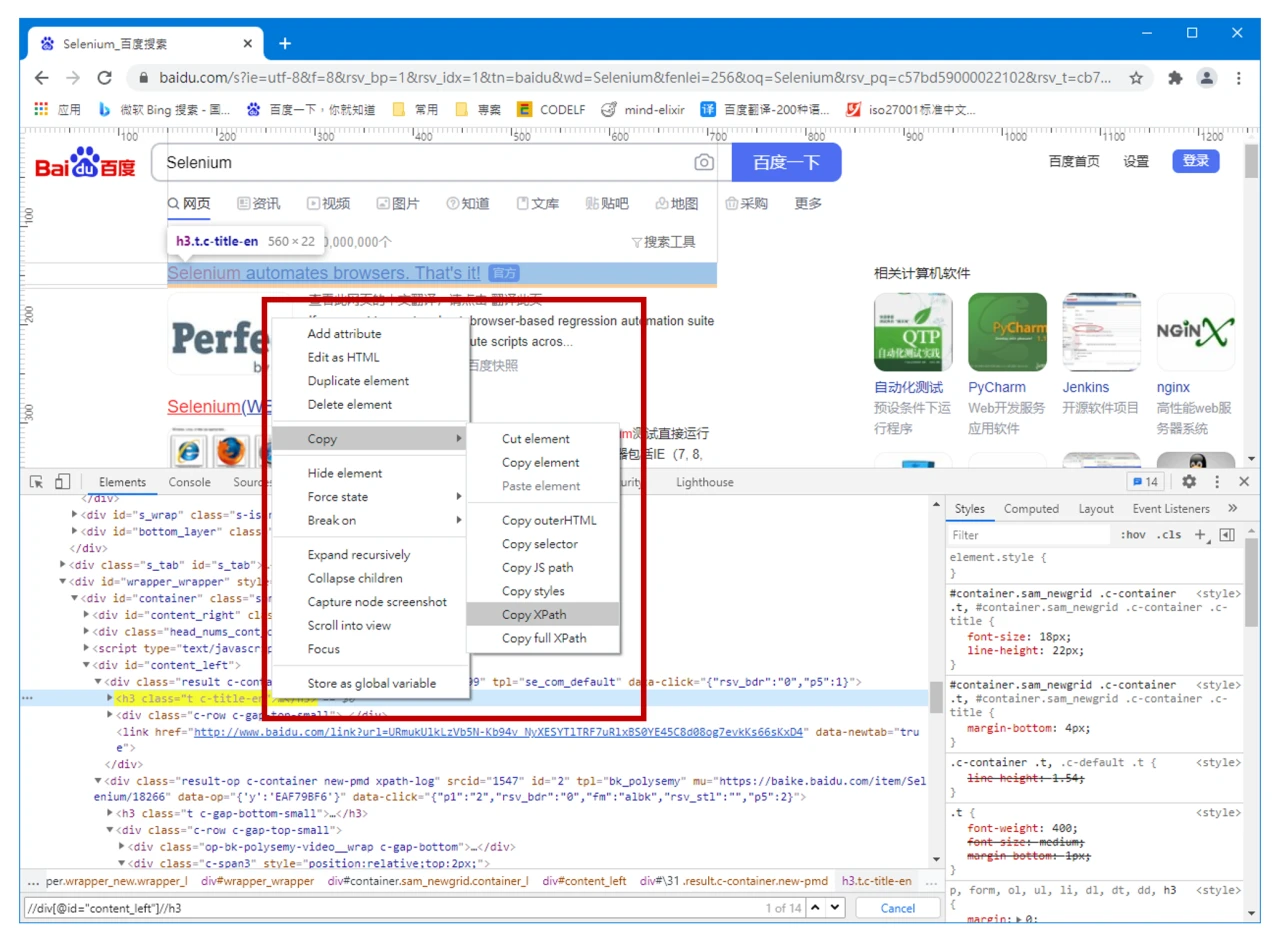
右键点击元素,选择 Copy,可复制元素的信息,包括 XPath 和 CSS 选择器文本。不过,考虑到层级关系可能会变化,这种方式得到的查找文本仅供临时使用,不推荐将此作为主要的获取选择器文本的方式。
元素的方法
获取元素后,可以对元素进行操作。
WebElement 类的常用方法如下:
click():单击clear():清除文本框的内容get_attribute(name):返回元素参数(HTML 方面的)get_property(name):返回元素属性(JS 方面的)is_selected():是否选择(对于单选框或复选框)is_enabled():是否启用send_keys(*keys):输入文本或按键is_displayed():是否显示screenshot(filename):输出屏幕截图(PNG)到给定文件。错误返回False,成功返回Truevalue_of_css_property(property_name):返回元素的给定 CSS 属性值
由此可以得出,代码第 9、10 行
1 | driver.find_element(By.ID, 'kw').send_keys('Selenium') |
的含义为:
- 找到 ID 为
kw的元素,输入 Selenium - 找到 ID 为
su的元素,单击
等待
由于网页的元素加载有一定的时间需求,一些元素可能在请求完毕后不会立即显示,而是要一段时间后显示。如果贸然查找或操作还没有加载完毕的元素,会报错。因此,等待在 Web 自动化测试中非常重要。
最简单的方法是硬等待,使用 time.sleep() 方法。如代码第 11 行:
1 | time.sleep(1) |
就是等待 1 秒。
此外,Selenium 也提供隐式等待和显式等待等方法,不过比较复杂,如果有时间的话,我以后会出一期讲这个。
驱动的属性
WebDriver 和 WebElement 类有一些属性可以使用。WebDriver 类常用的属性有下面几个:
title:标题current_url:当前 URLpage_source:页面源码
所以代码第 12 行:
1 | print(driver.title) |
就是打印出页面的标题。
寻找多个元素
除了寻找一个元素外,Selenium 也可以同时寻找所有符合条件的元素。
对应的方法,只是名称中把 element 改成了 elements,包括那些别名方法。比如:
1 | driver.find_element(By.ID, 'kw') |
有人可能觉得:一个页面中就只有一个 ID,不会有多个元素吧。实际上,ID 说是只能有一个,但是如果你给多个元素赋同样的 ID,页面还是能显示的,就是会在控制台有警告。当然,如果 CSS 和 JS 中涉及到这个 ID,那么会出现一些异常。
寻找多个元素的方法,返回一个列表,列表各项为 WebElement 实例,表示每一个符合条件的元素。如果没找到元素,则不会报错,返回空列表。
所以代码第 13 行:
1 | results = driver.find_elements(By.XPATH, '//div[@id="content_left"]/div[not(@tpl="recommend_list")]//h3') |
就是查找页面所有符合所给的 XPath 的元素,存到 results 中。
元素的属性
WebElement 类常用的属性有下面几个:
tag_name:标签名text:文本信息(不包括输入框里面的值,对于这种值,请使用get_property('value')获取)size:尺寸(返回字典{'height': H, 'width', W})location:坐标(返回字典{'x': X, 'y', Y})screenshot_as_base64:截图,返回 Base64 数据screenshot_as_png:截图,返回 PNG 二进制数据
所以代码第 14 ~ 16 行:
1 | title_list = [result.text for result in results] |
表示:
- 遍历
results,取其中各元素的文本,返回一个列表; - 打印列表各项的序号和值
关闭浏览器
所有操作完成之后,记得关闭浏览器驱动。
代码最后两行:
1 | driver.close() |
分别表示:
- 关闭页面
- 退出浏览器驱动
课件
本文课件地址:https://static.a4ding.com/doc/auto_test/0001_selenium_python_basic.pdf
















