XPath 选择器

XPath 选择器
丁俊尧上篇讲解 Selenium 的入门知识时,挖了几个坑,其中一个就是本文。
XPath 和 CSS 选择器在 Web 自动化测试中应用非常广泛,它们可以精准定位元素。如果精通这两个选择器中的其中一种,就可以很好地进行自动化测试脚本的编写。本文中,我将从 Web 自动化测试的角度来介绍这两个选择器(所以与其无关的功能我可能就不讲了,涉及到各自的术语的地方也不会太细,毕竟真正搞懂并不容易)。
因为篇幅太长,我就把这两个选择器分开说明。即使如此,内容还是很复杂,还请大家耐心阅读。
简介
XPath 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
HTML 可以视为一种不严格的 XML,所以也可以用 XPath 进行元素的查询。
了解元素
在了解这两个选择器之前,我们应该了解 HTML 标签中元素之间的关系。
元素、属性和值
我们先从一段简单的 HTML 标签开始:
1 | <div class="ding-class ding-class1 ding-class2" id="ding-id">text</div> |
上面一段中,整个 div 标签是一个元素,div 是标签名。
该元素的属性有两个:
- 属性名为
class,值为ding-class ding-class1 ding-class2 - 属性名为
id,值为ding-id
该元素的文本为 text。
元素间的关系
元素间的关系,主要有自身(self)、先辈(ancestor)/后代(descendant)、父(parent)子(child)、同胞(sibling)、前(preceding)后(following)。
这些关系从字面上应该很好理解。我这边主要说明一下先辈/后代与父子关系的区别:父子关系只包括直接从属的关系;而先辈/后代关系不仅包括直接从属,而且还包含间接从属的关系。
我们看一个较为完整的简单的 HTML 代码(之后的讲解绝大多数都以这个为例):
1 |
|
对于 id 为 test 的 li 元素而言:

它的父元素为 id 为 an_1 的 ul 元素;
它的先辈元素,除了父元素外,还有:
id为an_2的div元素id为an_3的body元素id为an_4的html元素

它的子元素有:
id为de_1的ul元素id为de_4的ul元素id为de_7的ul元素
它的后代元素,除了子元素外,还有:
id为de_2的li元素id为de_3的li元素id为de_5的li元素id为de_6的li元素id为de_8的li元素
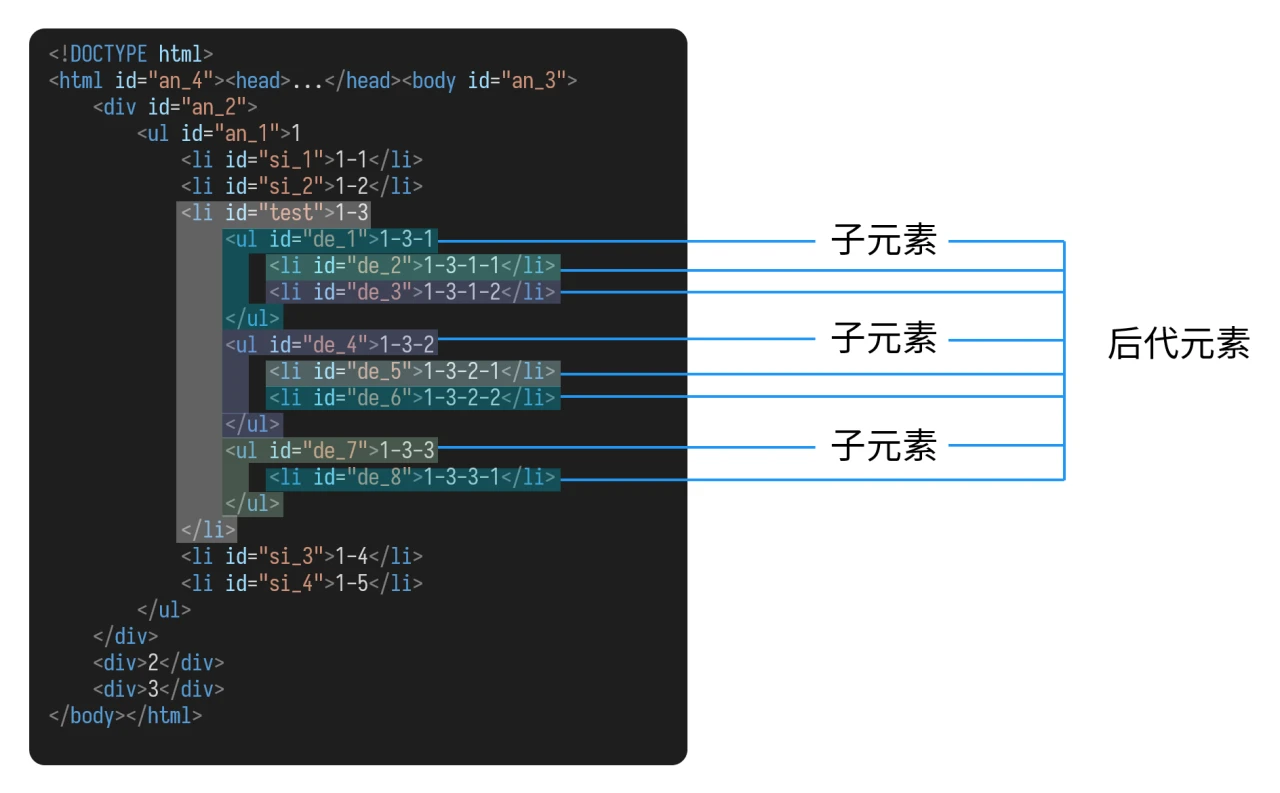
它的同胞元素中,
- 在它之前的同胞元素有:
id为si_1的li元素id为si_2的li元素
- 在它之后的同胞元素有:
id为si_3的li元素id为si_4的li元素

基本选取元素方式
绝对路径与相对路径
首先,XPath 有绝对路径和相对路径之分。如果路径以 / 开头,则为绝对路径,否则为相对路径。
绝对路径是相对于整个 HTML 代码而言的。
相对路径只能在特定情况下使用,如在 Selenium 中,对于 WebElement 实例使用:
1 | a = driver.find_element(By.XPATH, '//div[@id="content_left"]') |
上面的代码中,a 使用的是绝对路径,b 使用的是相对路径。
标签
如果要查询某个标签名的元素,直接输入标签名即可。如 div、p。
全体
表示全体的符号为 *,为选取之前的元素下的所有元素,不管什么标签都可以。
如果使用绝对路径查询全体:
1 | /* |
一般会选择 html 元素。
属性
在标签后加上方括号 [],方括号内写这个元素的属性,表示选取符合该条件的元素。
下标
在属性中写上数字,表示选取第几个元素。
注意:XPath 中的下标从 1 开始,与绝大多数编程语言不一样!
如:
1 | div[3] |
表示选取第三个 div 元素——更确切地说,是路径下 div 元素中的第三个。
参数
在参数名前加上 @,写在属性里,表示选取具有该参数的元素。如:
1 | div[@id] |
表示选取具有 id 属性的 div 元素。
@参数名=值 表示选取参数为某个值的元素,如:
1 | li[@id="test"] |
表示选取 id 属性为 test 的 li 元素。
文本值用单引号、双引号包裹都可以,只要统一就行,看个人习惯。不过,如果你要将其应用于编程,最好用你包裹字符串用的引号不一样的引号,免去转义的麻烦:
1 | driver.find_element(By.XPATH, '//div[@id="content_left"]') |
子元素与后代元素
要查询元素 a(父元素)下的子元素 b,则可以在父元素后接上 /,再接上子元素:
1 | a/b |
这种方法可以一直做下去。
如果要查询元素 a(先辈元素)下的后代元素 b,则接上 //:
1 | a//b |
// 很多情况下用在一段 XPath 语句的开头,这样可以直接定位元素,免去写元素前面的 /html/body/… 这样无用的层级,节约开发时间,增加易读性。比如示例中定位 id 为 test 的 li 元素,可以直接写:
1 | //li[@id="test"] |
而不用写成:
1 | /html/body/div[1]/ul/li[@id="test"] |
当然,前提是能够定位准确。
父元素
查询元素的父元素,可以用 .. 表示。如:
1 | //li[@id="test"]/../li[1] |
选取的是示例中 id 为 test 的 li 元素的父元素的第一个 li 子元素,也就是 id 为 si_1 的元素。
聪明的你应该发现了,XPath 和文件路径的表达方式很像——所以有时候我们就叫“XPath 路径”;也能想到, . 表示自己。
运算与常用函数
基本运算
XPath 语法中支持加减乘除(+ - * div)、取余(mod)、比较(= != < > <= >=)、逻辑(and or not())运算。
注意,XPath 中的除法为 div 代替,取余用 mod,等于只需要写一个等号。逻辑运算的“与”和“或”分别用 and 和 or 连接,而“非”使用 not() 函数表示。
如:
1 | //li[not(@index div @alt < 6)] |
表示选取不符合“index 属性除以 alt 属性的结果小于 6”这个条件的 li 元素。如果一个 li 元素的这两个属性不能进行运算(如其中一个为文本),或者是缺少这两个属性中的任意一个,也会被选取。如果应用于下面的 HTML 代码:
1 | <div> |
则文字为 1、7 的 li 元素不会被选取,其他的会被选取。
可以使用圆括号提高运算优先级,不过使用情况比较有限,基本上是包裹整个路径,或者在属性内使用。
选取第几个元素
前面我们说了如何选取第几个元素,现在说点高级的。
选取最后一个元素,在方括号中用 last()。如:
1 | //li[@id="test"]/../li[last()] |
选取的是示例中 id 为 test 的 li 元素的父元素的最后一个 li 子元素,也就是 id 为 si_4 的元素。
如果要选取倒数第几个元素,也可以如法炮制,如:
1 | //li[@id="test"]/../li[last()-1] |
选取的是示例中 id 为 test 的 li 元素的父元素的倒数第二个 li 子元素,也就是 id 为 si_3 的元素。
方括号中还可以使用 position() 函数表示被选取元素的序号,可与限定条件一起使用。如:
1 | //li[@id="test"]/../li[position()<3] |
选取的是示例中 id 为 test 的 li 元素的父元素的前两个 li 子元素,也就是 id 为 si_1、si_2 的元素。
选取多个路径
多个路径可以通过使用 | 来连接,表示选择满足任意一个路径的条件的元素。如:
1 | //ul[@id="de_1"] | //li[@id="si_3"] |
选取的是示例中 id 为 de_1 的 ul 元素,以及 id 为 si_3 的 li 元素。
文字
text() 函数表示元素的文字。该功能在 Web 自动化测试时,较常用于定义属性。如:
1 | //li[text()="1-3-3-1"] |
选取的是文本为 1-3-3-1 的 li 元素,即 id 为 de_8 的 li 元素。
注意:该函数取的文本不包括后代元素的文本,且如果有换行、空格和缩进,也会算进去。如果换行和缩进之间被其他元素隔开,也会被分隔为两个部分。比如对示例执行:
1 | //li[@id="test"]/text() |
实际上选取了四处:
1 | > $x('//li[@id="test"]/text()') |
因此,如果执行下面的语句,选取不到任何内容:
1 | /li[@text="1-3"] |
包含与连接,以及选取特定 class 的内容
contains(a, b) 函数表示在 a 中包含 b。
在选取带 class 属性的值时,会遇到一个元素的 class 属性有多个的情况:
1 | <div class="ding-class">text</div> |
现在需要选取 class 属性带有 ding-class 的 div 元素,如果使用
1 | //div[@class="ding-class"] |
只会选取第一个元素。
如果使用如下的语句,就能够选取这三个元素:
1 | //div[contains(@class, "ding-class")] |
表示 class 属性包含 ding-class 的 div 元素。
但是,这还不够,比如这种情况:
1 | <div class="ading-class">text</div> |
使用上面的语句,也会把这两个元素选中,这不是我们想要的。
我们有一个取巧的方法,在两个查询文本左右都加上空格。给 ding-class 加上空格简单,在字符串两边加空格就可以了;但是给 @class 加空格,就要用到 concat() 函数。
concat(a, b, ...) 函数表示连接括号里面的字符串。
对于上面的需求,只要把代码写为:
1 | //div[contains(concat(" ", @class, " "), " ding-class ")] |
这样就能够精确选取了。
以某字符串开头
starts-with(a, b) 函数表示 a 以 b 开头。由于和包含很像,就不赘述了。
轴
对于同胞元素、先辈元素等情况,我们可以利用一个称之为“轴”的概念。
轴的比较完整的用法如下:
1 | 之前的元素/轴::标签[条件或下标] |
表示之前的元素的轴中,符合条件或下标的标签。
对于 Web 自动化测试,相关的轴有以下:
parent:父元素(相当于..)ancestor:先辈元素ancestor-or-self:先辈元素与自身child:子元素descendant:后辈元素(相当于//)descendant-or-self:后辈元素与自身preceding:之前的元素following:之后的元素preceding-sibling:之前的同胞元素following-sibling:之后的同胞元素
主要是后面两个比较常用。
直接说还是比较难懂,还是看一下示例吧。
还是之前的例子,使用如下的语句:
1 | //li[@id="test"]/preceding-sibling::* |
表示选取示例中 id 为 test 的 li 元素之前的所有同胞元素,也就是 id 为 si_1 和 si_2 的 li 元素。
不过有一点需要注意,如果涉及到下标,是根据该元素的位置,从近到远排序的,而不是按照代码中的顺序排序!如:
1 | //li[@id="test"]/preceding-sibling::*[1] |
选取的是示例中 id 为 si_2 的 li 元素,因为它离 id 为 test 的 li 元素最近。
书写选择器文本的诀窍
善用工具
一般的浏览器的开发人员工具都提供了对这两个选择器的支持,可以参照之前的文章,在浏览器中调试选择器文本。
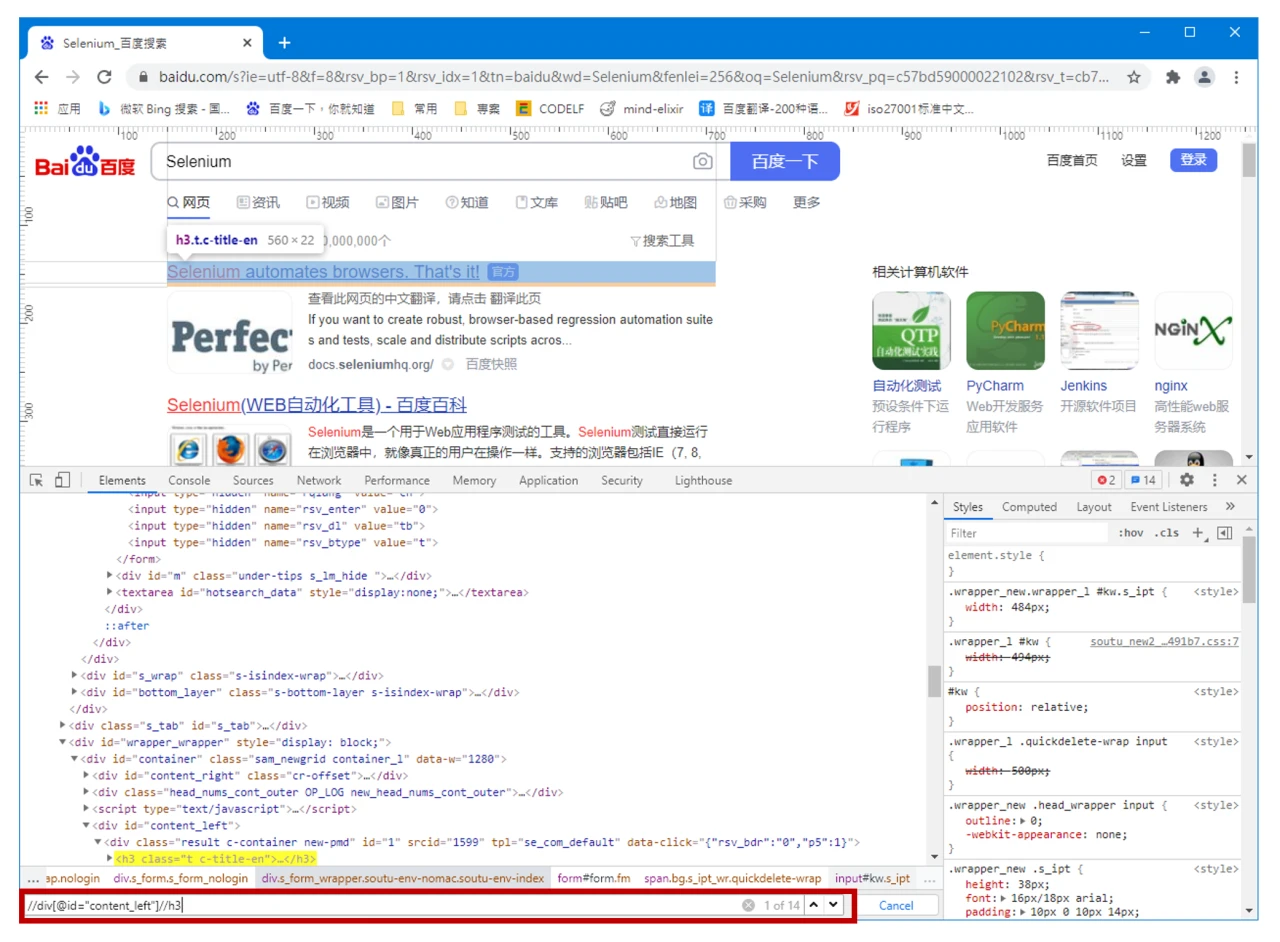
避免使用自动生成、层级过多、多处使用下标的嵌套
由于 Web 框架可能会变动层级和元素,这样的查询语句很容易查询不到想要的元素。建议使用一些标志性的特征来定位。如:
1 | //*[@id="post-XPath"]/div[1]/main/div[2]/div/div[2]/div/p |
后者明显比前者要好。
课件
本文课件地址:https://static.a4ding.com/doc/auto_test/0002_xpath_selector.pdf
















